10.メモ欄の取得
1.内容の確認
メモ欄を使用するにあたって、メモ欄の内容が
どのように扱われているのかを知らなければ、話になりません。
データベースで、メモ欄のある項目は、
アイテム、武器、防具、スキル、エネミー、ステートの6項目です。
データベースで設定した値は、$data_xxxx に格納されています。
さらに、プロパティ名を調べるには、ヘルプの「RPGVX データ構造体」の項目を見ます。
例えば、エネミーだと RPG::Enemy ですね。
そのページの一番下にありますね。「note メモ」
ですので、$data_enemies[n].note とすれば、エネミーのメモが取得できるわけです。
では、次の文章を1番のエネミーのメモ欄に記入して、中身を見てみます。

どうやら、改行を含む文字列で管理されているみたいですね。
$data_xxxx の詳細な使い方は、ヘルプの「データベース」項目を参照してください。
どのように扱われているのかを知らなければ、話になりません。
データベースで、メモ欄のある項目は、
アイテム、武器、防具、スキル、エネミー、ステートの6項目です。
データベースで設定した値は、$data_xxxx に格納されています。
さらに、プロパティ名を調べるには、ヘルプの「RPGVX データ構造体」の項目を見ます。
例えば、エネミーだと RPG::Enemy ですね。
そのページの一番下にありますね。「note メモ」
ですので、$data_enemies[n].note とすれば、エネミーのメモが取得できるわけです。
では、次の文章を1番のエネミーのメモ欄に記入して、中身を見てみます。
スライム
2行目
4行目
どうやら、改行を含む文字列で管理されているみたいですね。
| スキル | $data_skills[n].note |
| アイテム | $data_items[n].note |
| 武器 | $data_weapons[n].note |
| 防具 | $data_armors[n].note |
| エネミー | $data_enemies[n].note |
| ステート | $data_states[n].note |
2.特定の文字が含まれるか
では、メモ欄に特定の文字が含まれるかを判定してみましょう。
今回は、含まれるかどうかを調べるだけなので、include?メソッドを使用します。
注意点としては、BCD を調べるとき、ABCDE という文字があれば含まれると判断される点です。
このメソッドを使用する場合は、出来るだけ長くしたり、
特殊な記号を入れてダブらない文字にする必要があります。
例としては、*ABCD_EFG_H や <ABC_DEF_GH> などです。
例えば、キーアイテムを設定するためにメモ欄に <KEY_ITEM> と入力する場合は、
今回は、含まれるかどうかを調べるだけなので、include?メソッドを使用します。
注意点としては、BCD を調べるとき、ABCDE という文字があれば含まれると判断される点です。
このメソッドを使用する場合は、出来るだけ長くしたり、
特殊な記号を入れてダブらない文字にする必要があります。
例としては、*ABCD_EFG_H や <ABC_DEF_GH> などです。
例えば、キーアイテムを設定するためにメモ欄に <KEY_ITEM> と入力する場合は、
if $data_items[1].note.include?("<KEY_ITEM>")
print "キーアイテムだよ!"
end
のようになります。3.特別な値を取得する
文字の検索だけではなく、ゲーム内で使用するための値を取得したい場合もあります。
例えば、アイテムの売却価格とか。
*SELL_PRICE[100] や *SELL_PRICE[10%] などの値を取得したい場合は、次のようにします。
別の方法として、matchメソッドを使用するものもあります。
例えば、アイテムの売却価格とか。
*SELL_PRICE[100] や *SELL_PRICE[10%] などの値を取得したい場合は、次のようにします。
if /\*SELL_PRICE\[(\d+)([%])?\]/i =~ $data_items[1].note if $2 # %の処理 print "購入価格の #{$1} %" else # 数値の処理 print "売却価格は #{$1} G" end end正規表現を使用する場合は、主に上と同じものを私は使用しているのですが、
別の方法として、matchメソッドを使用するものもあります。
$data_items[1].note.match(/\*SELL_PRICE\[(\d+)([%])?\]/i)
4.複数の項目を取得する
一度に複数の項目を取得するには、scanメソッドを使用します。
例えば、成長効果を複数設定したいときなどに
<PARAM_HP:100> や <PARAM_MP:30> などの値を取得し配列にまとめます。
文字列から数値への変換には、to_iメソッドを使用します。
Object#instance_variable_setは、attr 処理されていないインスタンス変数に
外部からアクセスするためのメソッドです。
例えば、成長効果を複数設定したいときなどに
<PARAM_HP:100> や <PARAM_MP:30> などの値を取得し配列にまとめます。
for param in item.note.scan(/<PARAM_(.*?):(\d+)>/i)
case param[0].upcase
when "HP"
print "HP:#{param[1]}"
when "MP"
actor.instance_variable_set(:@maxmp_plus, param[1].to_i)
end
end
メモ欄の数字は、文字列なので数値として扱うには、変換が必要になります。文字列から数値への変換には、to_iメソッドを使用します。
Object#instance_variable_setは、attr 処理されていないインスタンス変数に
外部からアクセスするためのメソッドです。
5.すべての内容を1行区切りの配列で取得する
メモ欄の内容を1行ごとに区切った配列で取得するには、
obj.note.split("\r\n")のようにします。
obj.note.split("\r\n")のようにします。
p *obj.note.split("\r\n")
イテレータを使用すればすべての行を調べられますし、必要なら行数も取得できます。
obj.note.split("\r\n").each_with_index do |s,i|
case s
when "<KEY_ITEM>"
p "#{i+1} 行目:#{s}"
when /\*SELL_PRICE\[(\d+)\]/
p "#{i+1} 行目:#{$1}"
end
end
6.正規表現の例
正規表現については、ヘルプで詳しく説明されているのでそちらを見てください。
[RGSS リファレンス] - [付録] - [正規表現]
ヘルプだけでは分かりにくい箇所は、こちらで説明しています。
正規表現でグループを作った部分は、後で取得することが出来ます。
() を使用した順に番号が割り当てられ、$1、$2、$3 ... と続きます。
正規表現を使用するたびに、この変数は上書きされるので注意しましょう。
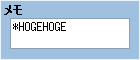
*HOGEHOGE という文字にマッチさせます。

*HOGE_PIYO や *HOGE_FUGA という文字にマッチさせます。
//i は、大文字・小文字を区別しないというオプションなので、
マッチした文字が大文字か小文字か分からないため、大文字に変換しています。

*HOGE[100] や *HOGE[20%] などの *HOGE[数字] という文字にマッチさせます。
数値での指定だけでなく、パーセントを使用した割合での2種類の設定方法を同時に判定しています。
直前のグループ、つまり % が付いていれば、$2に "%" を入れ、
無ければ、$2はnilとなります。
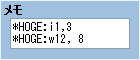
*HOGE:i1,3 や *HOGE:w12, 8 などの *HOGE:識別子+数字, 数字 という文字にマッチさせます。
識別子の意味としては、i:アイテム、w:武器、a:防具 みたいな感じで作ってます。
今回の場合は、アイテムの種類+ID, 個数 みたいなイメージ。
これは、[]内のどれか1文字にマッチします。
\s?は、スペースの有無です。/ ?/としても同じ意図したものになります。
"1,2,3" と詰めて記述したり、"1, 2, 3" と1マス空けて記述したりできます。
好みの問題になりますが、私が作るものは大体入れてます。
無くても全然OKです。
それと、数を制限したくない場合は、\s*とすればスペースをいくらでも入れることが出来ます。

*HOGE[0] や *HOGE[1, 2,3] などの []内の数字が複数ある文字にマッチさせます。
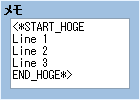
<*START_HOGE から END_HOGE*> までの複数行に渡る文字にマッチさせます。
[RGSS リファレンス] - [付録] - [正規表現]
ヘルプだけでは分かりにくい箇所は、こちらで説明しています。
正規表現でグループを作った部分は、後で取得することが出来ます。
() を使用した順に番号が割り当てられ、$1、$2、$3 ... と続きます。
正規表現を使用するたびに、この変数は上書きされるので注意しましょう。
*HOGEHOGE という文字にマッチさせます。
note = "*HOGEHOGE"
if note.match(/\*HOGEHOGE/i)
end
*HOGE_PIYO や *HOGE_FUGA という文字にマッチさせます。
note = "*HOGE_PIYO\r\n*HOGE_FUGA"
if note.match(/\*HOGE_(PIYO|FUGA)/i)
case $1.upcase
when "PIYO"
when "FUGA"
end
end
upcaseは、小文字から大文字へ変換する処理です。//i は、大文字・小文字を区別しないというオプションなので、
マッチした文字が大文字か小文字か分からないため、大文字に変換しています。
*HOGE[100] や *HOGE[20%] などの *HOGE[数字] という文字にマッチさせます。
数値での指定だけでなく、パーセントを使用した割合での2種類の設定方法を同時に判定しています。
note = "*HOGE[100]\r\n*HOGE[20%]" if note.match(/\*HOGE\[(\d+)([%])?\]/i) if $2 # パーセントの処理 else # 通常の数値の処理 end end?は、直前の正規表現の有無を表しますので、
直前のグループ、つまり % が付いていれば、$2に "%" を入れ、
無ければ、$2はnilとなります。
*HOGE:i1,3 や *HOGE:w12, 8 などの *HOGE:識別子+数字, 数字 という文字にマッチさせます。
識別子の意味としては、i:アイテム、w:武器、a:防具 みたいな感じで作ってます。
今回の場合は、アイテムの種類+ID, 個数 みたいなイメージ。
note = "*HOGE:i1,3\r\n*HOGE:w12, 8"
if note.match(/\*HOGE:([IWA])(\d+),\s?(\d+)/i)
case $1.upcase
when "I"
item = $data_items[$2.to_i]
when "W"
when "A"
end
value = $3.to_i
end
識別子の判別は、(I|W|A) としても良いですが、1文字ですので [] の文字クラスを使用します。これは、[]内のどれか1文字にマッチします。
\s?は、スペースの有無です。/ ?/としても同じ意図したものになります。
"1,2,3" と詰めて記述したり、"1, 2, 3" と1マス空けて記述したりできます。
好みの問題になりますが、私が作るものは大体入れてます。
無くても全然OKです。
それと、数を制限したくない場合は、\s*とすればスペースをいくらでも入れることが出来ます。
*HOGE[0] や *HOGE[1, 2,3] などの []内の数字が複数ある文字にマッチさせます。
note = "*HOGE[1,2, 3, 4,5]" p note.scan(/\*HOGE\[((?:\d+,\s?)*(?:\d+))\]/i).to_s.split(/,\s?/) # => ["1", "2", "3", "4", "5"]String#splitメソッドは、指定されたパターンで分割し配列に格納するものです。
<*START_HOGE から END_HOGE*> までの複数行に渡る文字にマッチさせます。
note = "<*START_HOGE\r\nLine 1\r\nLine 2\r\nLine 3\r\nEND_HOGE*>" p note[/^<\*START_HOGE\r\n(.+)END_HOGE\*>/im, 1].split(/\r\n/) # => ["Line 1", "Line 2", "Line 3"]//m は、正規表現記号.が改行にもマッチするようになります。